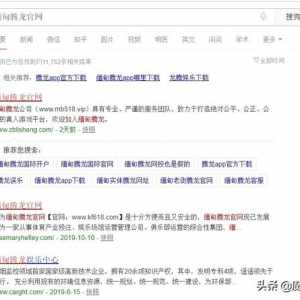
由於跟上一篇文章有的手段接近,因此這裡就一起寫的話比較容易理解。我們先來上圖:
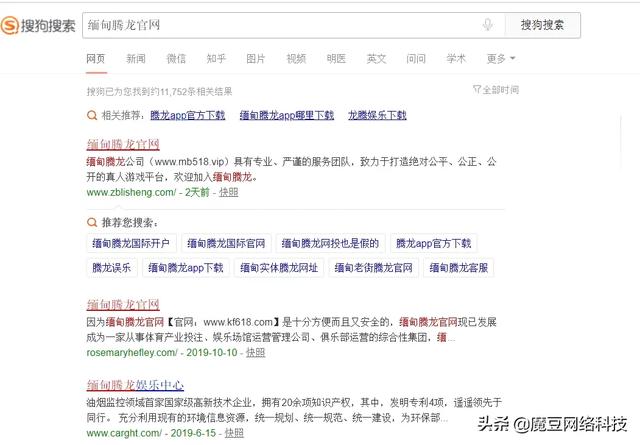
可以看到,跟昨天差不多的黑帽關鍵詞哈,這次用搜狗的,因為目前搜狗對這類站點似乎比較友好?這都不是重點,這幾個站看起來像是被黑的,又像是站群。不管了,who care?
我們打開第一個站點,看看:

內容看起來很正規哦,本著學習的目的,當然不能這麼算了。來看看它的源碼:
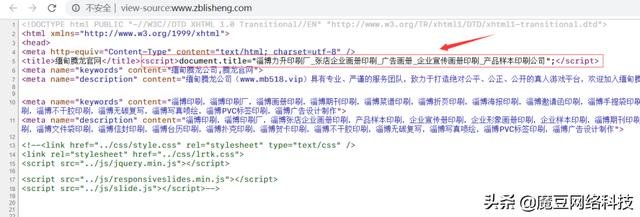
可以看到,它這個是通過js來重寫了標題,讓人看起來像是正規的。這種手法很常見,不說了,發現這個不是我今天要找的站點,跳過找下一家。
一番尋找之後,看到了這家,看看頁面內容都是正常的:
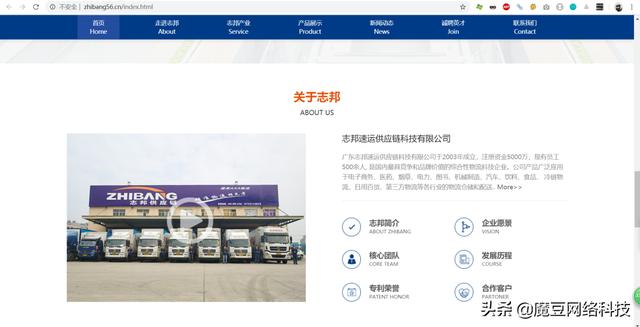
所以,看看源碼:
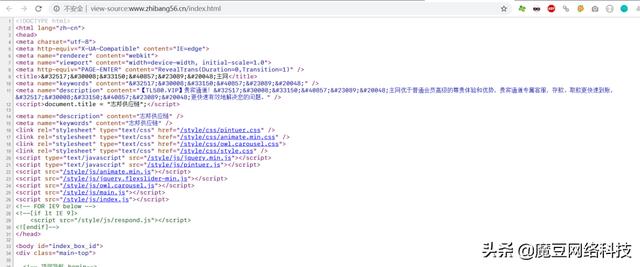
看到了麽,TDK的部分文字被編碼了。很明顯的是對文字進行了HTML編碼,我們用代碼還原一下他們的真面目:

可以看到,這個就是它的真實標題而已:
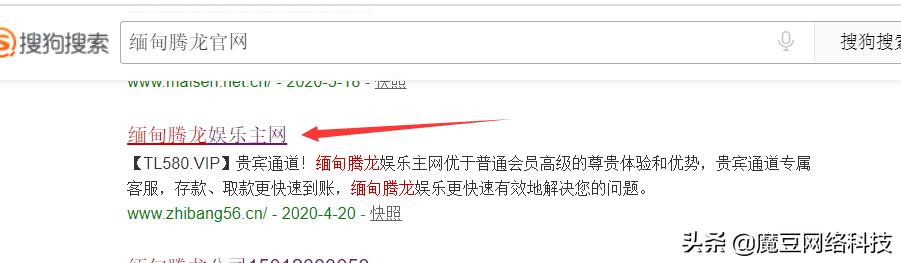
那麼,問題來了,為啥要辛辛苦苦這麼乾?
從seo的角度出發的話,肯定就是為了更好的收錄和排名唄。我們先從收錄說起,畢竟沒有收錄,後面的都扯淡。影響收錄的因素有很多哈,其中占比比較重要的就是一個內容的原創度啦,那麼這樣子做是為了讓內容的原創度更高麽?顯然不是的,我們看下,頁面的主題部分源碼:

看到了麽?正文部分的源碼並沒有採取這樣的操作,而只是在TDK部分,涉及到關鍵詞的部分才這麼乾。那顯然,之前的猜測是錯誤的,根本就不是為了原創。原創的問題後面再說,那麼這樣做的原因是啥?
我們想要瞭解別人的做法,就得站在別人的角度去思考問題。想想看,他們這些詞都是啥關鍵詞呀?都是些違禁詞是吧,那要做這些詞的收錄和排名得先逃過搜索引擎的違禁詞過濾系統吧,怎麼做?變身唄,你看到的我不是真實的我。

經過變身之後,終於逃過了第一道防線(至少目前還是可以的),第二道防線如何破?得有個身份才行,那就搞個企業站的外殼吧,畢竟企業嘛,看起來都正規。所以可以看到很多CB類的站群都是用企業站的外殼,只做首頁詞。這樣收錄和排名都不錯。因為本身這些詞並沒有什麼競爭度,所以seo裡面的那些什麼關鍵詞密度,內容質量啥的,統統靠邊去。只要標題裡面出現關鍵詞就ojbk了。況且用首頁的話,那麼內容隨機調用一下就是很好的聚合頁原創了。而且做的是站群,哪有那麼多的時間去搞那麼多精細化的東西。都是測試出來一個東西有用,一套模板效果好,然後猛懟就完事。
有點跑偏了哈,回到正題。知道了這麼做的原因之後,那麼如何把文字變成HTML編碼呢?可以看到這些編碼都是咋弄的,模板就是數字; 這樣的,那就是把文字變成數字就好啦,上一篇文章也講過,將中文變成數字,就是拿到中文的Unicode碼值就OK。有了思路,就是乾:
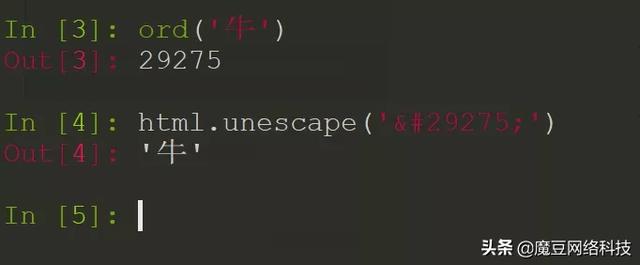
驗證通過,封裝成一個函數接口,好方便調用:
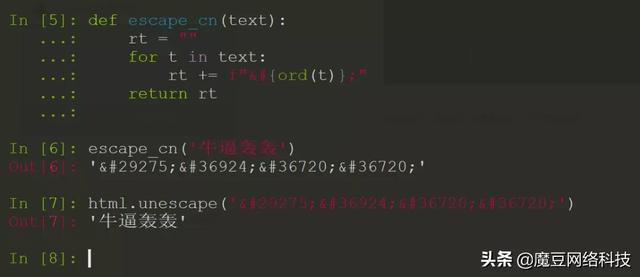
搞完收工,就是這麼簡單。
我們學習別人的東西,不僅僅是要知道實現,更主要的就是要知道為什麼這麼做。瞭解了原因之後你才能更好的進步,單純的複製粘貼是得不到什麼提升的。
本文僅僅是做技術交流,請勿學習用於非法用途!
如果你有更好的發現和不同的觀點,也歡迎一起交流學習。
今天的分享就到這裡,喜歡的話就轉發點個贊唄?
